Follow-up on polymorphism in Rust |
2014-03-04 |
This is a short revision of my previous post on polymorphism in Rust. By posting a link to that article on the Rust subreddit I received a lot of insightful feedback from the community. By the way, I find it really nice how welcoming the Rust community is. Thanks, everybody.
The following points were made (among others):
- First of all, I was only emulating polymorphic behaviour previously, since there was no real alteration of the type actually used in my code
- One can use for loops and iterators and all these nice functional tools in the standard library and they are not even slow
- The heap allocation was to blame for the slower performance of the version using traits
To address these issues I revised part of the programs and split the trait version into two, one of which allocates on the stack, the other on the heap. Now, to be fair, I don't think the stack-allocated variant retains the run-time flexibility of the heap-allocated one but they can solve the same problem, as long as you are willing to recompile if you want to change something.
Furthermore, I applied more fancy language features such as the iterators mentioned above and a closure to wrap the call to the computational kernel – by the way I am beginning to feel more comfortable using closures in Rust, which is something I've mostly been avoiding in other languages so far.
I also extended the made-up problem a little bit by requiring different kernels depending on whether the looping index is odd or even. This actually requires some sort of dispatch even in the dumb imperative variant, where I handled it with a simple if-else-clause. The more abstracted variants have the decisive advantage at this point that they separate the dispatch mechanism from the computation that is done.
Suffice it to say, that the source code has grown quite substantially, so I will simply link the new tag here, instead of posting the whole thing. The results look as follows:
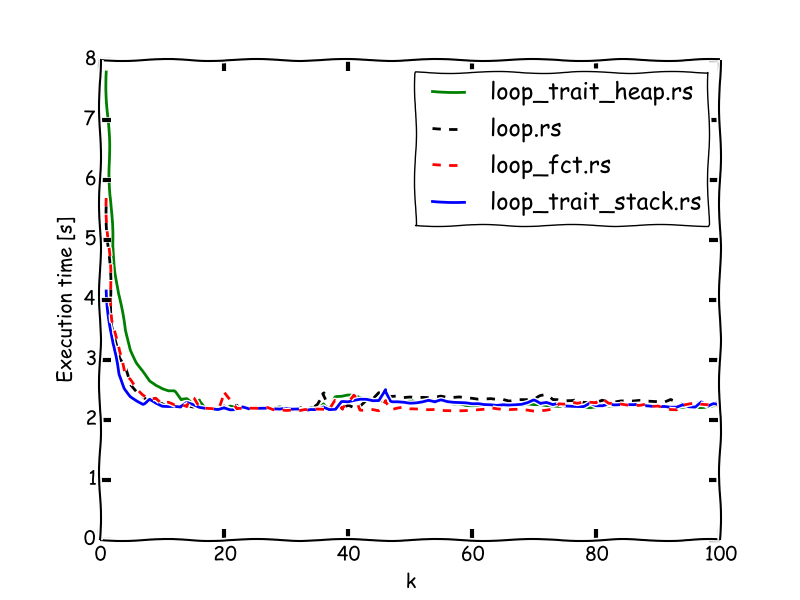
The fact, that the highly refactored and abstracted version is even faster than
the imperative approach for low k is just great. (If you haven't read the
previous article, k is a measure for the complexity of computational kernel.)
This really reassures me to trust rustc and LLVM.
However, the heap-allocated variant is still somewhat slower. Considering the potential flexibility this harbours though, this is in most cases probably an acceptable cost though.
This new version is probably still not entirely what I had in mind but close enough. In practice, the kernel could probably become some property of the elements being iterated over. However, it remains to be seen whether this is what it looks like. I'd really like to adapt some of these benchmarks to more useful code to be written for triton at some point.
